机器学习被广泛定义为“利用经验来改善计算机系统的自身性能”。事实上,“经验”在计算机中主要是以数据的形式存在的,因此数据是机器学习的前提和基础。
在第一期格物汇的文章中,我们介绍了工业数据预处理的方法,主要针对数据格式异常,数据内容异常等问题进行了简要探讨。做数据预处理的主要目的是将杂乱无章的数据规整成我们想要的矩阵、表格、张量等结构,方便在之后的机器学习中进行模型训练。然而数据中的问题还包含了冗余,噪声,高维度,体量大等很多问题。解决这些问题的方法与数据预处理的方法在机器学习中被统称为特征工程,今天我们就来了解一下吧。
特征工程是什么
当你想要你的预测模型性能达到最佳时,你要做的不仅是要选取最好的算法,还要尽可能的从原始数据中获取更多的信息。那么问题来了,你应该如何为你的预测模型得到更好的数据呢?这就是特征工程要做的事,它的目的就是获取更好的训练数据。
维基百科中给特征工程做出了简单定义:特征工程是利用数据领域的相关知识来创建能够使机器学习算法达到最佳性能的特征的过程。简而言之,特征工程就是一个把原始数据转变成特征的过程,这些特征可以很好的描述这些数据,并且利用它们建立的模型在未知数据上的表现性能可以达到最优(或者接近最佳性能)。从数学的角度来看,特征工程就是人工地去设计输入变量X。
特征工程的重要性
关于特征工程(Feature Engineering),已经是很古老很常见的话题了,坊间常说:“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”。由此可见,特征工程在机器学习中占有相当重要的地位。
1、特征越好,灵活性越强
只要特征选得好,即使是一般的模型(或算法)也能获得很好的性能,因为大多数模型(或算法)在好的数据特征下表现的性能都还不错。好特征的灵活性在于它允许你选择不复杂的模型,同时运行速度也更快,也更容易理解和维护。
2、特征越好,构建的模型越简单
有了好的特征,即便你的参数不是最优的,你的模型性能也能仍然会表现的很nice,所以你就不需要花太多的时间去寻找最有参数,这大大的降低了模型的复杂度,使模型趋于简单。
3、特征越好,模型的性能越出色
显然,这一点是毫无争议的,我们进行特征工程的最终目的就是提升模型的性能。
特征工程怎么做
既然特征工程这么重要,那么我们就来看看特征工程到底是如何实现或者工作的。特征工程到底分为哪些内容?我们大致可以参考如下流程图来看看。
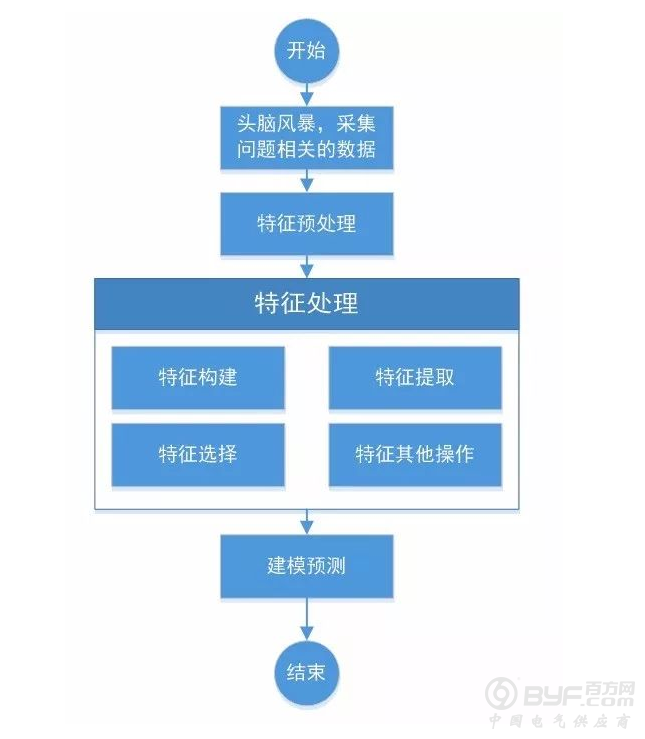
简单来说,特征处理主要分如下三个方法:
特征构建
特征构建是指从原始数据中人工的找出一些具有实际意义的特征。需要花时间去观察原始数据,思考问题的潜在形式和数据结构,对数据敏感性和机器学习实战经验能帮助特征构建。除此之外,属性分割和结合是特征构建时常使用的方法。特征构建是个非常麻烦的问题,书里面也很少提到具体的方法,需要对问题有比较深入的理解。
特征抽取
一些观测数据如果直接建模,其原始状态的数据太多。像图像、音频和文本数据,如果将其看做是表格数据,那么其中包含了数以千计的属性。特征抽取是自动地对原始观测降维,使其特征集合小到可以进行建模的过程。通常可采用主成分分析(PCA)、线性判别分析(LDA))等方法;对于图像数据,可以进行线(line)或边缘(edge)的提取;根据相应的领域,图像、视频和音频数据可以有很多数字信号处理的方法对其进行处理。
特征选择
不同的特征对模型的准确度的影响不同,有些特征与要解决的问题不相关,有些特征是冗余信息,这些特征都应该被移除掉。特征选择是自动地选择出对于问题最重要的那些特征子集的过程。常用的特征选择方法可以分为3类:过滤式(filter)、包裹式(wrapper)和嵌入式(embedding)。
小结
总的来说,数据会存在各种各样的问题,针对这些问题我们的特征工程给出了相应的解决办法:1.特征解释能力不足,我们可以尝试使用特征构建,对数据进行升维来提升特征解释能力;2.特征冗余,维度太高,噪声太多,我们可以通过特征抽取和特征选择,来对数据进行降维去噪,提炼特征。当然还有其他的特征处理方法,一般需要根据具体问题而定。