REAL-f公司创始人北川修三是在印刷厂工作时想到这个创意的,他花了两年时间开发,将面部数据从高质量照片转换为3D面具的方法,并于2011年开始销售面具。REAL-f公司表示:“之前是用黑白照片,后来发展到彩色照片,现在,我们要让大家进入3D立体时代。”在制作面具之前,公司的专家们会使用精密的拍摄工具从各个不同角度拍摄顾客想要的面孔,然后通过电脑将照片素材整合成3D图像,最后再使用“人体影印机”将人脸图像印制到特定的材料上,整个制作过程大概需要花费两周的时间,制成效果能以假乱真,异常逼真。

这种面具有个明显的用例,就是使用它们来进行人脸识别测试。一家日本汽车公司订购了沉睡表情的面具,以改进其面部识别技术,用以训练其检测司机打瞌睡的行为。苹果也用同样的高仿真面具,测试利用Face ID登录iPhone X功能。
以上的应用有个共通属性,那就是它们都属于人脸识别。而传统的人脸识别实际上属于图像处理加机器学习,就是从图像找出人脸区域,从人脸区域回归出人脸形状(特征点),再通过特征点计算出特征值,对比时通过对两者的特征值进行一系列的运算得出相似度,其中的转变过程非常复杂,实际操作的对象就是图片像素点的灰度值,收到了图片影响较多,如光线较强,背景复杂程度,遮挡、眼镜、胡子以及角度,夜里摄像头无法照亮面部时,也无法使用。
一、人脸识别技术概述
人脸识别是指利用分析比较人脸视觉特征信息进行身份鉴别的计算机技术,其可以定义为:输入查询场景中的静止图像或者视频,使用人脸数据库识别或验证场景中的一个人或者多个人,通常也被称为面部识别、人像识别。人脸识别具有非强制性、非接触性、并发性等特点,因此研究者在上世纪六、七十年代就开始了人脸识别技术的研究。进入九十年代后,随着高性能计算机的发展,人脸识别技术获得了重大突破。
美国国家标准技术局(NIST)举办的FRVT2006(Face RecognitionVendor Test 2006)通过大规模的人脸数据库测试表明,人脸识别技术的识别精度要比FRVT2002至少提高了一个数量级。部分识别算法的精度超过了人类的平均水平。对于高分辨率、高质量的正面人脸的识别率达到100%。
二、人脸识别技术的难点
虽然人脸识别技术经历了较长的研究阶段,但至今还是被认为是生物特征识别技术中较为困难的研究课题之一,其原因在于:
1.背景环境的复杂多样
在进行人脸识别前需要先对监控场景中的人脸进行定位,即人脸检测。人脸检测的正确与否直接影响人脸识别性能。当监控场景的背景较为复杂时,人脸检测率也会随之降低,因此能够适应复杂背景环境的人脸检测算法是人脸识别技术的难点之一。
2. 光照条件的复杂多变
在智能视频监控系统的实际应用中,会由于监控环境光线的变化造成检测到的人脸图像存在不同的阴暗变化,不同光照条件下人脸识别虽然在性能上比FRVT2002有显著提高,但是还没在根本上克服光照对识别率的影响。
3. 人脸表情的多样性
在实际应用过程中,人脸的表情随时都可能发生变化。当人的表情发生变化时,可能会引起人脸轮廓以及纹理的变化,同时由于面部肌肉的牵引,面部的特征点的位置也会随之改变。不同的表情引起面部的变化都不同,此外,不同的人的相同表情影响也不相同,因此很难用统一的标准来精确划分各种表情对不同人的影响。
4.采集人脸的角度多样性
人脸的角度多样性主要是指由于拍摄角度的不同导致检测到的人脸图像的旋转,包括平面旋转和深度旋转。表情变化对人脸图像的影响相同,拍摄角度的变化同样会导致人脸轮廓的变化,除此之外,由于角度的变化,可能会导致人脸的部分特征无法被正确提取,进一步导致人脸的错误识别。
5.遮挡问题
即使是非人为故意遮挡,在实际应用时检测到的人脸图像也经常会出现如帽子、眼镜等遮挡物,除了这些,胡子以及刘海的变化也直接影响人脸的特征提取,当人脸图像发生遮挡时,人脸的很多信息会丢失,导致人脸识别算法出错或失效。
三、目前国内人脸识别现状
目前国内做图像识别、人脸识别和视频识别的公司很多,但是真正脱颖而出的企业却极少,像是旷世科技Face++、商汤科技、极链科技Video++等,都是经过多年的技术积累,才有了现在的成果。以视频识别最为突出的极链科技Video++为例,Video++作为一家以AI产品技术为核心,驱动文娱新经济发展人工智能科技公司,公司对于人脸识别和视频识别都有丰富的技术积累。
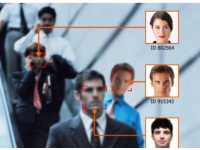
从技术层面出发,在视频识别过程中,Video++首先是对视频做一个镜头分割,在镜头片断里面做后续所有的识别检测工作。完成镜头分割之后进入到内容提取,对于人脸识别来说内容提取主要是两个步骤,一个人脸检测框的获取,另外一个是人脸的id识别。人脸检测框主要是两个步骤,一个是人脸检测,一个人脸跟踪。检测和跟踪有不同的特性,人脸检测速度比较慢,准确率比较高。由于跟踪用到了前后之间相互的运动关系,它的速度比较快,但是它的准确率相对于检测比较低。既要兼顾到准确率,同时又要兼顾到速度的要求。
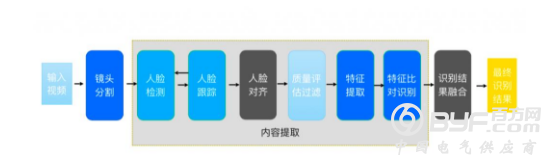
就是说一开始对人脸在全局范围内做一个检测。检测完之后做跟踪,跟踪过程当中需要用人脸检测对它进行一个校正。因为跟踪算法乳化性不太高,有时候会有一个偏移。怎么用人脸检测算法对它进行一个校正呢?在跟踪框周围小区域里面做一个局部检测,由于区域比较小检测开销就比较小。它的速度保证比较快,但是它的准确率又比跟踪输出的人脸框要高一些,在这个过程当中我们就可以用检测跟踪相结合的方式来提高准确率,同时又保证算法的速度不受影响。在过程之后我们就进行人脸的对齐,做完人脸对齐下面一个重要的步骤就是质量的评估。
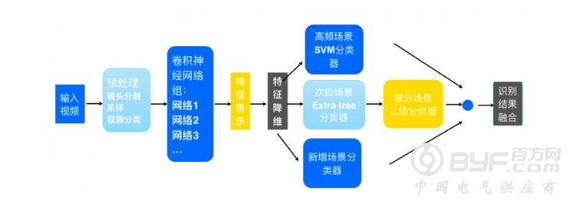
对采集到的序列进行质量评估,质量评估过程当中,找到质量比较好的那些采量。把那些质量比较差的采量进行丢弃。通过这一方法保留下来比较好的采样,对质量差的数据进行丢弃。这样就保证了很多噪声的干扰得到了一个去除。在质量评估之后对质量比较好的采样进行提取,然后进行特征比对。
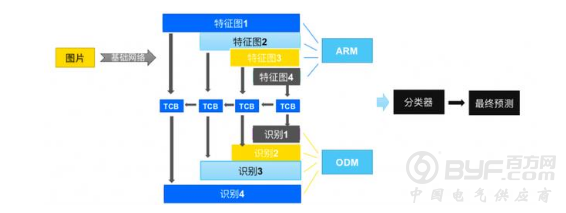
由于在整个采样序列上每一个帧它都会有一个识别结果,这些识别结果怎么进行一个融合,这里面可能会有一些噪声,去除后有一些识别错误的结果,这就需要涉及一个识别结果的融合机制。最后通过融合机制得到最终的一个识别结果。
在过去的五年里,计算机视觉飞速发展,使得许多基本的人脸识别任务比以往任何时候都更加精确和普遍,以至于亚马逊、谷歌、IBM和微软等科技巨头都将其作为现成的商品出售。然而,让机器去识别视频中正在发生的事情,却具有无限的挑战性,因为你不仅要在一张图片中处理对象、面孔和风景,还要处理时间、动作、事情和观点。好消息是,同样的发展也促进了当前图像识别的繁荣,即更好、更多的训练数据和更快、更便宜的计算能力——也促进了计算机视觉在视频上的应用。