甚至连以公信力著称的BBC也难以幸免,比如BBC北安普顿分站的推特账号就曾发过这样一条消息:Breaking News: President Trump is injured in arm by gunfire #Inauguration.(劲爆消息:特朗普总统在就职典礼后遭遇枪击,手臂受伤。)

至于国内的假新闻,也是花样百出,甚至微信对话也能伪造,PS技术出神入化,比如一度引爆互联网圈的这个截图:
雷锋网注:此截图被证实为经过PS伪造
AI系统:建立多维度向量进行数据检测
10月4日,麻省理工学院计算机科学与人工智能实验室(CSAIL)在其官网发布了一则新闻,宣称该实验室与卡塔尔计算研究所(Qatar Computing Research Institute)的研究人员合作,已经研究出一种可以鉴别信息来源准确性和个人政治偏见的AI系统,该研究成果将于本月底在比利时布鲁塞尔召开的2018自然语言处理经验方法会议(EMNLP)上正式公布。
研究人员用这个AI系统创建了一个包含1000多个新闻源的开源数据集,这些新闻源被标注了“真实性”和“偏见”分数。据称,这是类似数据集中收录新闻源数量最多的数据集。
研究人员写道:“打击‘假新闻’的一种(有希望的)方法是关注消息来源。”“虽然‘假新闻’(帖子)主要在社交媒体上传播,但他们仍然有最初来源,即某个网站,因此,如果一个网站曾经发布过假新闻,很有可能未来还会发布。”
AI系统的新颖之处在于它对所评估的媒介有广泛的语境理解,没有单独从新闻文章中提取特征值(机器学习模型所训练的变量),而是兼顾了维基百科、社交媒体,甚至根据url和web流量数据的结构来确定可信度。
该系统支持向量(SVM)训练来评估事实性和偏差,真实性分为:低、中、高;政治倾向分为:极左、左、中偏左、中偏右、右、极右。
根据该团队所述,系统只需检测150篇文章就可以确定一个新的源代码是否可靠。它在检测一个新闻来源是否具有高、低或中等程度的“真实性”方面的准确率为65%,在检测其政治倾向是左倾、右倾还是中立方面的准确率为70%。
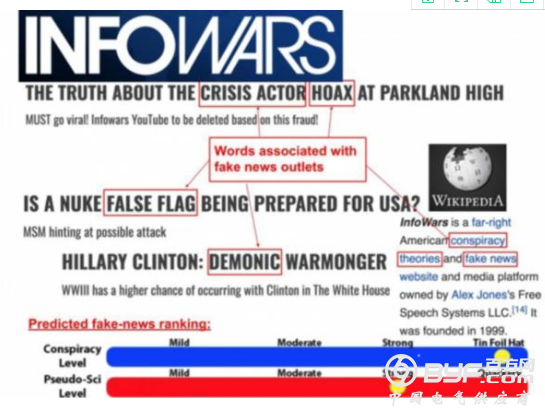
雷锋网注:AI系统分析示例
在上图显示的文章中,AI系统对文章的文案和标题进行了六个维度的测试,不仅分析了文章的结构、情感、参与度(在本例中,分析了股票数量、反应和Facebook上的评论),还分析了主题、复杂性、偏见和道德观念,并计算了每个特征值的得分,然后对一组文章的得分进行平均。
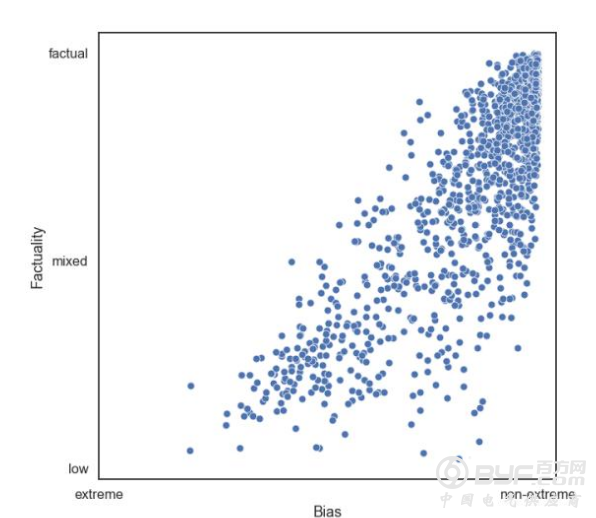
雷锋网注:“真实性-偏见”预测模型图
维基百科和Twitter也被加入了AI系统的预测模型。正如研究者们所言,维基百科页面的缺失也许说明了一个网站是不可信的,或者网页上可能会提到这个问题的政治倾向是讽刺的或者明显是左倾的。此外,他们还指出,没有经过验证的Twitter账户,或者使用新创建的没有明确标注的账户发布的消息,不太可能是真的。
该模型的最后两个向量是URL结构和web流量,可以检测试图模仿可信新闻来源的url(例如,“foxnews.co”),参考的是一个网站的Alexa排名,该排名根据网站总浏览量进行计算。
该团队在MBFC(Media Bias/Fact Check )网站的1066个新闻源上对此AI系统进行了训练。他们用收集的准确性和偏见数据手工标注网站信息,为了生成上述数据库,研究人员在每个网站上发布了10-100篇文章(总计94,814篇)。
正如研究人员在他们的报告中煞费苦心的介绍所示,并不是每一个特征值都能有效预测事实准确性或政治偏见。例如,一些没有维基百科页面或建立Twitter档案的网站有可能发布的信息是公正可信的,在Alexa排名靠前的新闻来源并不总是比流量较少的新闻源更公正或更真实。
研究人员有一个有趣的发现:来自虚假新闻网站的文章更有可能使用夸张和情绪化的语言,左倾媒体更有可能提到“公平”和“互惠”。与此同时,拥有较长的维基百科页面的出版物通常更可信,那些包含少量特殊字符和复杂子目录的url也是如此。
未来,该团队打算探索该AI系统是否能适应其他语言(它目前只接受过英语训练),以及是否能被训练来检测特定区域的偏见。他们还计划推出一款App,可以通过“跨越政治光谱”的文章自动回复新闻。
该论文的第一作者、博士后助理拉米巴利(Ramy Baly)表示:“如果一个网站以前发布过假新闻,他们很可能会再次发布。”“通过自动抓取这些网站的数据,我们希望我们的系统能够帮助找出哪些网站可能首先这么做。”
当然,他们并不是唯一试图通过人工智能打击假新闻传播的机构。
总部位于新德里的初创公司metaFact利用NLP算法来标记新闻报道和社交媒体帖子中的错误信息和偏见;SAAS平台AdVerify.ai于去年推出beta版,可以分析错误信息、恶意软件和其他有问题的内容,并可以交叉引用一个定期更新的数据库,其中包含数千条虚假和合法的新闻。
前文中也提到过,Facebook一度深陷假新闻的泥淖,已经开始尝试使用“识别虚假新闻”的人工智能工具,并于近期收购了总部位于伦敦的初创公司Bloomsbury AI,以帮助其鉴别消除假新闻。
假新闻会被消除吗?
然而,一些专家并不相信人工智能可以胜任这项任务。卡内基梅隆大学机器人研究所(Carnegie Mellon University Robotics Institute)的科学家迪恩波默洛(Dean Pomerleau)在接受外媒 the Verge 采访时表示,人工智能缺乏对语言的微妙理解,而这种理解是识别谎言和虚假陈述所必需的。
“我们最初的目标是建立一个系统来回答‘这是假新闻,是或不是?’”他说,“但我们很快意识到,机器学习无法胜任这项任务。”
但是,人类事实核查者做的不一定比AI更好。今年,谷歌暂停了“事实核查”(Fact Check)这一标签,该标签曾位于谷歌新闻报道栏,此前保守派媒体也曾指责谷歌对他们表现出了偏见。
不过,无论最终鉴别假新闻和个人偏见的解决方案是AI系统还是人工,抑或两者兼而有之,假新闻被彻底消除的那一天都不会立刻到来。
据咨询公司Gartner预测,到2022年,如果目前的趋势不变,大多数发达国家的人看到的虚假信息将会多于真实信息。

