【引言】
在元素周期表内多达一百多种的元素中,存在着大量潜在的新材料可用于应对我们当前遇到的技术难题和社会挑战。然而,由于缺乏导向性,特别是对于某些受制备过程影响较大的材料体系,从海量的组成空间中搜索可行方案是一个相当缓慢和昂贵的过程。
【成果简介】
近日,美国SLAC国家加速器实验室的Apurva Mehta(通讯作者)课题组和西北大学、芝加哥大学的研究人员合作,在Science Advances上发表了题为“Accelerated discovery of metallic glasses through iteration of machine learning and high-throughput experiments”的文章。作者通过基于前期报道的观察、物理化学理论的参数,训练机器学习模型,形成合成测量方法来知道高通量实验,用于寻找哟中Co-V-Zr三组元非晶合金体系。实验观察和模型预测可以很好地符合,但在精确组成预测上存在着定量差异。作者将这些差异用于机器学习模型的再训练,优化后的模型的精确度显著题提升,不仅体现在Co-V-Zr体系,而且涵盖了现有的其他有效数据。此后,作者使用优化后的模型来指导发现了两种额外的未经报道的三元系非晶合金。
【图文导读】
图1:结合机器学习迭代和高通量实验来快速且有导向性地进行材料探索的模型的示意图。
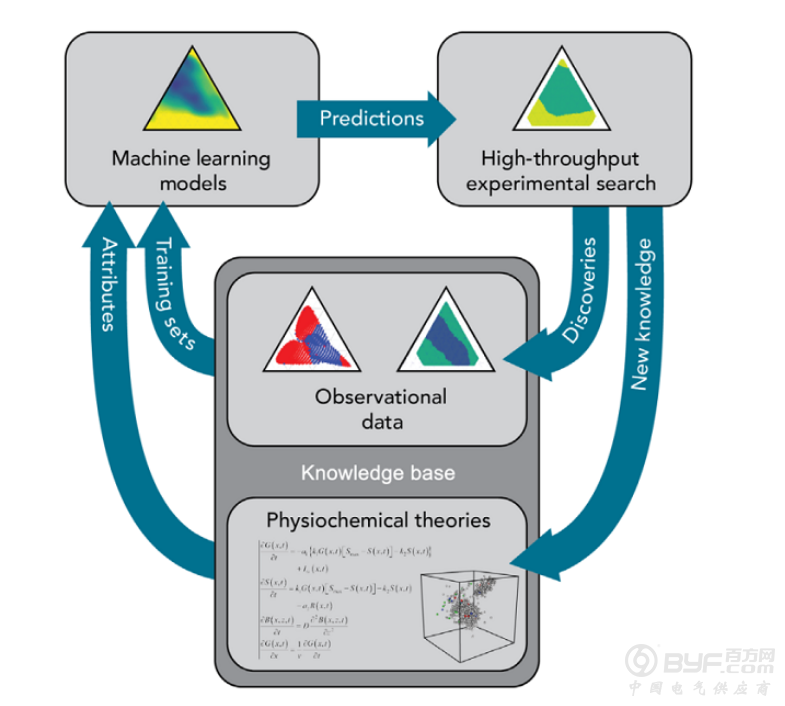
图2:用于非晶合金形成的机器学习模型的性能和预测结果。

(A)预测甩带非晶形成能力模型的相对工作特征曲线和LB手册中甩带实验数据得相互验证;
(B) 甩带和堆积模型的相对工作特征曲线和LB手册中磁控溅射法合成的非晶合金的实验数据的相互验证;
(C&D) 对熔体纺丝(C)和共沉淀溅射方法(D)合成Co-V-Zr非晶形成液体的预测。
图3:第一代机器学习模型和生化理论的比较。

(A)基于Yang和Zhang理论的高玻璃形成可能性的预测;
(B)基于有效堆积模型的玻璃形成可能性的预测;
(C)结合两种生化理论的机器学习模型对玻璃形成可能性的预测。
图4:新型高通量实验结果和第一代预测的比较。

(A)机器学习模型结合生化理论对溅射共沉积的玻璃形成可能性的预测;
(B)在高通量XRD实验中测得的第一衍射峰的半高宽;
(C)基于非晶硅的XRD测量的第一衍射峰半高宽所得的玻璃形成阈值,对玻璃形成可能性的分布预测。
图5:机器学习模型的更新一代。

(A)Co-V-Zr三元系的修正预测;
(B)三元系中未被发现的最大玻璃形成区域的预测;
(C)第一、第二和第三代模型的相对工作特征曲线比较,以及和所有现有的溅射共沉积合成数据的相互验证。
图6:第一代和第二代预测结果和Co-V-Zr,Co-Fe-Zr,Fe-Ti-Nb三元系的高通量实验结果相比较。

(A1-A3)第一代机器学习模型的玻璃形成可能性预测;
(B1-B3)第二代机器学习模型的修正结果;
(C1-C3)高通量实验的XRD测量的第一衍射峰的半高宽;
(D1-D3)应用C1-C3数据的非晶硅玻璃形成阈值的玻璃形成区域的实验分布。
【小结】
本文通过机器学习迭代和高通量实验的方法,研究人员可以快速发现三种新的玻璃形成体系,并具有定量准确性,合成对制备方法敏感的材料,此种方法对其他材料和与合成路径相关的材料性质同样有效,这对于用现有的物理化学理论来预测是相当难的。






